目录
- 1、什么是redis
- 2、应用场景
- 3、DB数据结构
- 3.1、`RedisDB`数据结构:`redis`数据库默认有`16`个库。
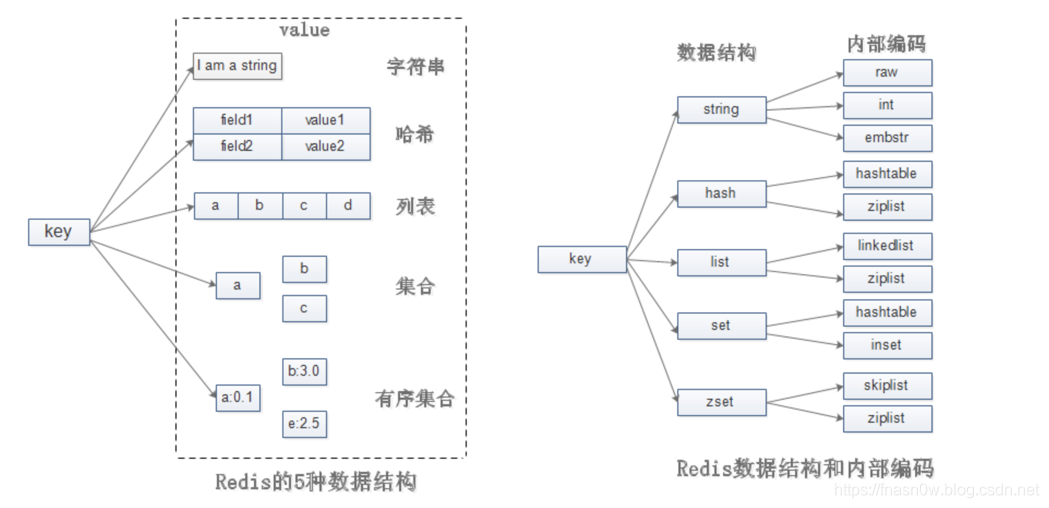
- 3.2、Redis的五种数据结构的内部编码
- 4、String数据结构
- 4.1、redis3.2以前sds
- 4.1、redis3.2后sds
- 5、bitMap(bitset,位图)数据结构
- 6、list数据结构
- 6.1、redis阻塞队列实现
- 6.2、list底层实现
- 6.2、ziplist压缩列表
- 6.3、quicklist快速列表
- 7、hash数据结构
- 8、set数据结构
- 8.1、intset数据结构
- 9、ZSet数据结构
- 9.1、skiplist跳表数据结构
- 9.2、ZSet的skiplist跳表实现
- zset应用
1、什么是redis

2、应用场景
1、缓存
2、如下

3、DB数据结构
存储海量数据的数据结构:
1、链表 :内存是零散的
2、B+ tree :内存是零散的
3、数组 :内存是连续的O(1)。
但是redis里的key,不一定是数值类型,可以把key做一个hash,转成整形,但是不能直接用,这个值是很大的【亿级】,需要与数组长度取余,hash(key)=亿级整形数a=a%数组.size=【0-数组size】
redis使用数组【哈希表】存储数据,出现hash冲突怎么办?
redis使用链表解决。
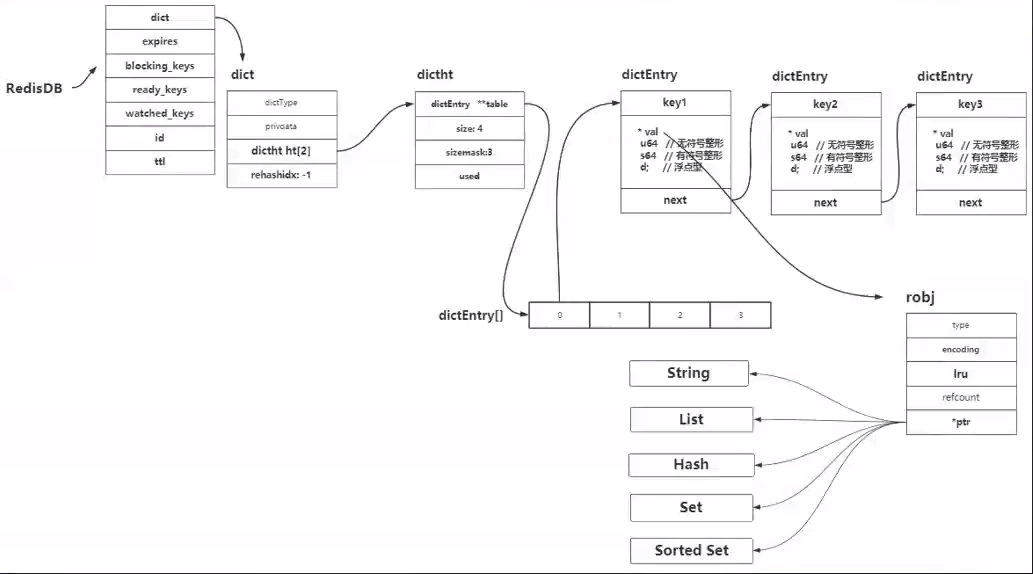
3.1、RedisDB数据结构:redis数据库默认有16个库。
每个库的数据结构:有一个重要字段dict,叫字典,所有的数据都是通过字典索引的。

字典的数据结构:dictht就是哈希表【就是一个数组】

dictht的数据结构:
size:以O(1)的时间复杂度获取长度
sizemask:
used:当前数组用了多少元素
dictEntry:表示数组中的每一个元素,**tablel是一个指针,指向数组

dictEntry的数据结构:
*key:存储数据的key
*val:它是一个指针,指向RedisObject
*next:发生hash冲突时,生成链表,这个next指向下一个节点

RedisObject :
type:redis5中数据类型【String,list,hash,set,zset】,都说是通过它来表示的。4bit
encoding:数据编码。4bit
lru:记录时间的,24个bit存储
refcount:计数器法,对象是否存活的一个判断。4字节
*ptr:指向真实数据对象的存储。8字节
整个对象=16byte

DB数据结构整体:
3.2、Redis的五种数据结构的内部编码
4、String数据结构
https://www.cnblogs.com/programlearning/p/6924593.html
https://blog.csdn.net/qq_33996921/article/details/105226259
127.0.0.1:6379> set some_string "asd"
OK
127.0.0.1:6379> type some_string
string
127.0.0.1:6379> object encoding some_string 返回给定key所储存的值所使用的内部
"embstr"
字符串类型的内部编码有三种:
1、int:存储 8 个字节的长整型(long,2^63-1)。
2、embstr:代表 embstr 格式的 SDS(Simple Dynamic String 简单动态字符串),
存储小于 44 个字节的字符串,只分配一次内存空间(因为 Redis Object 和 SDS 是连续的)。
3、raw:存储大于 44 个字节的字符串(3.2 版本之前是 39 个字节),需要分配两次内存空间(分别为 Redis Object 和 SDS 分配空间)。
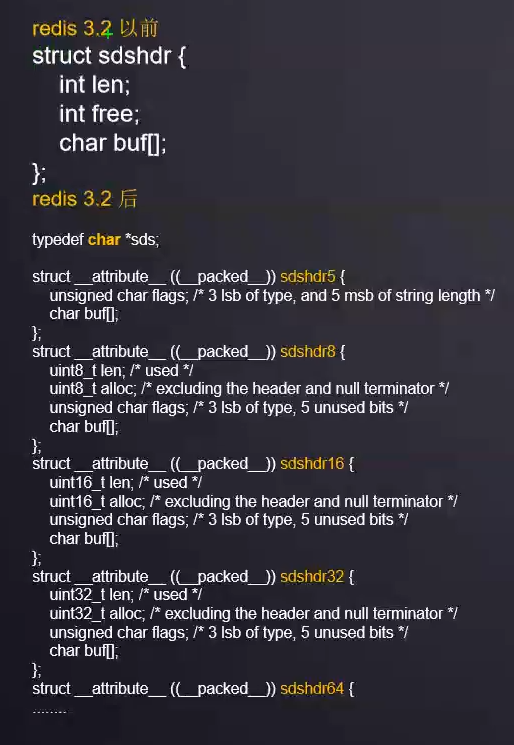
4.1、redis3.2以前sds
len:表示数据长度
int free:分配的内存空间,剩余可用空间的长度
char buf[]:数据空间
缺点:假设就存一个字符i,就一个字节,那么len就占用了4字节,free也占了4字节,光这两个字段就占用了8字节,但是实际上数据才1字节,因此,对于小数据来说是非常浪费空间的。
4.1、redis3.2后sds
1、redis在3.2之后,定义了非常多的字符串类型【sdshdr5/sdshdr8/sdshdr16/sdshdr32/sdshdr64】
2、字符串构建的时候,长度小于32,使用sdshdr5,看上图,sdshdr5只有两个字段【flags,buf】
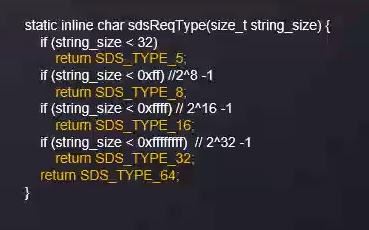
3、sdshdr5数据结构:
flags占用1byte,分为8bit,前三表示类型,后三表示数据长度。
缺点是不能表示动态的数组,通常不会使用它,sdshdr5会转成sdshdr8
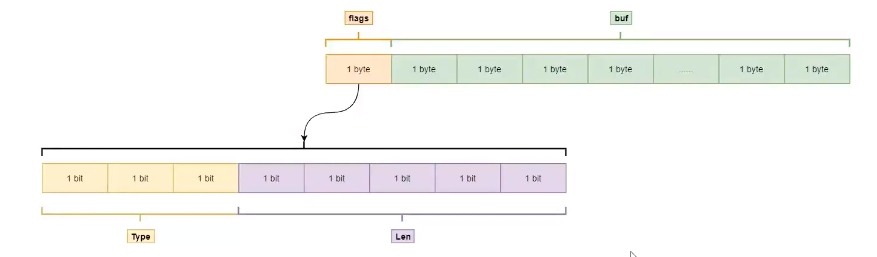
4、sdshdr8数据结构
len:占1byte,数据长度
alloc:占1byte,分配的内存大小
flags:占1byte
buf[]:会在数据后加1字节(\0结束符)
5、embstr原理与cpu缓存行
RedisObject的大小是16byte,然后在使用sdshdr8去存储字符串,整个数据大小就是3字节+业务数据大小+1字节。
cpu缓存行的大小是64byte。
如果业务数据是44byte或者小于44byte,加上20byte,就小于等于64byte,
embstr : redisObject(16)+sdshdr8 {char(44个) + 3 + 1(\0结束符)} =64
正好等于一个cpu缓存行的大小,如果满足这个条件,那么分配数据的时候,就会挨着RedisObject进行分配,这样正好数据和RedisObject在同一个cpu缓存行内,进行数据读取的时候,cpu寻址通dictEntry的val,找到RedisObject,通过RedisObject直接拿到值,而不需要RedisObject的ptr再次寻址找数据了,embstr原理就是这个。embstr只分配一次内存空间(因为 Redis Object 和 SDS 是连续的)
embstr的内存结构:

6、row原理
一旦业务数据超过44个字节,整体的大小超过64个字节,在Redis中将认为是一个大的字符串,不再使用 emdstr 形式存储,存储结构将变为raw。需要分配两次内存空间(分别为 Redis Object 和 SDS 分配空间)。
7、int原理
如果一个字符串内容可转为long,那么该字符串会被转化为long类型,使用指针ptr,对象ptr指向该long,并且对象类型也用int类型表示。
8、type类型
000=0表示sdshdr5
001=1表示sdshdr8
010=1表示sdshdr16
011=1表示sdshdr32
100=1表示sdshdr64

5、bitMap(bitset,位图)数据结构
https://blog.csdn.net/wufaliang003/article/details/82016385
https://www.cnblogs.com/wuhaidong/articles/10389484.html
平常接触最多的是5个入门级数据结构:String,Hash,List,Set,Sorted Set,还有高级数据结构:Bitmaps,Hyperloglogs,GEO。
1、bitMap:就是通过一个bit位来表示某个元素对应的值或者状态,其中的key就是对应元素本身。我们知道8个bit可以组成一个Byte,所以bitmap本身会极大的节省储存空间。由于string的最大长度是512m,所以bitmaps能最大设置2^32个不同的bit。
2、setbit命令介绍
指令 SETBIT key offset value
设置或者清空key的value(字符串)在offset处的bit值(只能只0或者1)。
3、案例
127.0.0.1:6379> setbit name 1 1
(integer) 0
127.0.0.1:6379> strlen name
(integer) 1
127.0.0.1:6379> setbit age 9 1
(integer) 0
127.0.0.1:6379> strlen age
(integer) 2
name :【0,1,0,0,0,0,0,0】8bit,1字节,在索引位置为1的位置设置值为1
age:【0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0】16bit,2个字节,在索引位置为9的位置设置值为1
4、使用场景1
最经典的就是用户连续签到
key 可以设置为: 前缀:用户id:年月
譬如:
setbit sign:123:201909 0 1
代表用户ID=123签到,签到的时间是19年9月份,0代表该月第一天,1代表签到了
第二天没有签到,无需处理,系统默认为0
查看用户123,2019年09月签到了多少次
127.0.0.1:6379> setbit sign:123:201909 0 1
0
127.0.0.1:6379> setbit sign:123:201909 2 1
0
127.0.0.1:6379> getbit sign:123:201909 0
1
127.0.0.1:6379> getbit sign:123:201909 1
0
127.0.0.1:6379> getbit sign:123:201909 2
1
127.0.0.1:6379> getbit sign:123:201909 3
0
127.0.0.1:6379> bitcount sign:123:201909 0 0
2
注:
语法:BITCOUNT key start end命令,被设置为1的位的数量。
计算key所储存的字符串值中,指定字节区间[start,end]被设置为1 的比特位的数量。
redis的setbit设置或清除的是bit位置,而bitcount计算的是byte位置,1byte=8bit
bitcount sign:123:201909 0 -1 -1表示最后一个元素的位置,时间复杂度O(N)
5、使用场景2
统计活跃用户
使用时间作为key,然后用户ID为offset,如果当日活跃过就设置为1
那么我该如果计算某几天/月/年的活跃用户呢(暂且约定,统计时间内只有有一天在线就称为活跃),有请下一个redis的命令
命令 BITOP operation destkey key [key …]
说明:对一个或多个保存二进制位的字符串 key 进行位元操作,并将结果保存到 destkey 上。
说明:BITOP 命令支持 AND 、 OR 、 NOT 、 XOR 这四种操作中的任意一种参数
20190216 活跃用户 【1,2】
20190217 活跃用户 【1】
统计20190216~20190217 总活跃用户数: 1
127.0.0.1:6379> setbit 20200201 1 1
(integer) 0
127.0.0.1:6379> setbit 20200201 2 1
(integer) 0
127.0.0.1:6379> setbit 20200202 1 1
(integer) 0
bitop and 取交集,获取这两天连续登陆的用户
bitop or 取并集,这俩天登陆的用户
127.0.0.1:6379> bitop and desk1 20200201 20200202
(integer) 1
127.0.0.1:6379> bitop or desk2 20200201 20200202
(integer) 1
127.0.0.1:6379> bitcount desk1
(integer) 1
127.0.0.1:6379> bitcount desk2
(integer) 2
6、list数据结构
由ZipList+QuickList组成。
6.1、redis阻塞队列实现
public class RedisQueueTest {
public static void main(String[] args) {
new Thread(new RedisQueue("192.168.169.129","queue-task")).start();
}
}
class RedisQueue implements Runnable{
private String hostname;
private String queueName;
private Jedis jedis;
//默认false
public static volatile boolean stop;
public RedisQueue(String hostname, String queueName) {
this.hostname = hostname;
this.queueName = queueName;
this.jedis=new Jedis(this.hostname);
}
@Override
public void run() {
//会消耗客户端资源和服务端资源
// 127.0.0.1:6379> lpush queue-task ab c c
// (integer) 3
// while(!stop){
// String lpop = this.jedis.lpop(this.queueName);
// if (!StringUtils.isEmpty(lpop)){
// System.out.println(lpop);
// }
// }
while(!stop){
//阻塞队列一
// 127.0.0.1:6379> lpush queue-task ab 6 6
// (integer) 3
// System.out.println("try again!!");
// List<String> blpop = this.jedis.blpop(5,this.queueName);
// if (blpop!=null && blpop.size()>0){
// System.out.println(blpop);
// }
//阻塞队列二
System.out.println("try again!!");
//brpoplpush从列表中取出最后一个元素,并插入到另外一个列表的头部;
//如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
//简单说,从队列queueName里弹出一个元素,并复制一份放到this.queueName + "_bak"队列里备份着
String brpoplpush = this.jedis.brpoplpush(this.queueName, this.queueName + "_bak", 5);
if (!StringUtils.isEmpty(brpoplpush)){
System.out.println(brpoplpush);
//模拟发生异常,数据没丢失,备份了
//发生异常后,keys *就能看到备份的队列,数据查看 lindex queue-task_bak -1或者lrange queue-task_bak 0 -1
if (true){
throw new RuntimeException();
}
//没有异常,需要删除备份的数据
//删除this.queueName+"_bak"队列里的,从左边开始的第一个元素brpoplpush
this.jedis.lrem(this.queueName+"_bak",-1,brpoplpush);
}
}
}
}
6.2、list底层实现
127.0.0.1:6379> lpush queue-task ab 6 6
(integer) 3
127.0.0.1:6379> type queue-task
list
127.0.0.1:6379> object encoding queue-task
"quicklist"
列表类型的内部编码有两种:
ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个),
同时所有值都小于hash-max-ziplist-value配置(默认64字节),Redis会使用ziplist作为哈希的内部实现。
linkedlist(链表):当列表类型午饭满足ziplist的条件时,Redis会使用linkedlist作为列表的内部实现。
quicklist(快速列表):3.2之后加入的新的数据结构quicklist,用作redis对外提供的五种数据类型—list的底层实现。
quickList 是 zipList 和 linkedList 的混合体,quicklist宏观上是一个双向链表,因此,它具有一个双向链表的有点,
进行插入或删除操作时非常方便,虽然复杂度为O(n),但是不需要内存的复制,提高了效率,而且访问两端元素复杂度为O(1)。
list是一个有序的数据结构,redis采用quicklist(双端队列)和ziplist作为list的底层实现。
6.2、ziplist压缩列表
https://blog.csdn.net/yellowriver007/article/details/79021049
https://blog.csdn.net/zxm342698145/article/details/80835665
当列表的元素个数小于list-max-ziplist-entries配置(默认512个),同时所有值都小于list-maxziplist-value配置(默认为64字节),Redis会使用ziplist做为哈希的内部实现。Ziplist可以使用更加紧凑的结构来实现多个元素的连续存储,所以在节省内存方面更加优秀。
一个典型的ziplist结构分布如下:
area |<---- ziplist header ---->|<----------- entries ------------->|<-end->|
size 4 bytes 4 bytes 2 bytes ? ? ? ? 1 byte
+---------+--------+-------+--------+--------+--------+--------+-------+
component | zlbytes | zltail | zllen | entry1 | entry2 | ... | entryN | zlend |
+---------+--------+-------+--------+--------+--------+--------+-------+
^ ^ ^
address | | |
ZIPLIST_ENTRY_HEAD | ZIPLIST_ENTRY_END
|
ZIPLIST_ENTRY_TAIL
zlbytes:表示整个ziplist占的空间
zltail:表示定位到最后一个节点的偏移量,可以快速的从尾部去遍历元素
zllen:表示ziplist中数据项(entry)的个数。
zllen字段因为只有16bit,所以可以表达的最大值为2^16-1。- 如果
<zllen>小于等于2^16-2(也就是不等于2^16-1),那么就表示ziplist中数据项的个数; - 否则,也就是
<zllen>等于16bit全为1的情况,那么就不表示数据项个数了,这时候要想知道ziplist中数据项总数,那么必须对ziplist从头到尾遍历各个数据项,才能计数出来。
<zlend>: ziplist最后1个字节,是一个结束标记,值固定等于255。
<entry>的构成:<prevrawlen><len><data>
prevrawlen:表示前一个数据项占用的总字节数。这个字段的用处是为了让ziplist能够从后向前遍历(从后一项的位置,只需向前偏移prevrawlen个字节,就找到了前一项)。这个字段采用变长编码。<len>: 表示当前数据项的数据长度(即<data>部分的长度)。也采用变长编码。<data>:真正的数据
prevrawlen说明:
- 如果前一个数据项占用字节数小于254,那么就只用一个字节来表示,这个字节的值就是前一个数据项的占用字节数。
- 如果前一个数据项占用字节数大于等于254,那么
<prevrawlen>就用5个字节来表示,其中第1个字节的值是254(作为这种情况的一个标记),而后面4个字节组成一个整型值,来真正存储前一个数据项的占用字节数。 - 为什么没有255的情况呢?
这是因为:255已经定义为ziplist结束标记的值了。在ziplist的很多操作的实现中,都会根据数据项的第1个字节是不是255来判断当前是不是到达ziplist的结尾了,因此一个正常的数据的第1个字节(也就是的第1个字节)是不能够取255这个值的,否则就冲突了。
<len>字段就更加复杂了,它根据第1个字节的不同,总共分为9种情况:
|00pppppp| - 1 byte。第1个字节最高两个bit是00,那么<len>字段只有1个字节,剩余的6个bit用来表示长度值,最高可以表示63 (2^6-1)。
|01pppppp|qqqqqqqq| - 2 bytes。第1个字节最高两个bit是01,那么<len>字段占2个字节,总共有14个bit用来表示长度值,最高可以表示16383 (2^14-1)。
|10__|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes。第1个字节最高两个bit是10,那么len字段占5个字节,总共使用32个bit来表示长度值(6个bit舍弃不用),最高可以表示2^32-1。需要注意的是:在前三种情况下,<data>都是按字符串来存储的;从下面第4种情况开始,<data>开始变为按整数来存储了。
|11000000| - 1 byte。<len>字段占用1个字节,值为0xC0,后面的数据<data>存储为2个字节的int16_t类型。
|11010000| - 1 byte。<len>字段占用1个字节,值为0xD0,后面的数据<data>存储为4个字节的int32_t类型。
|11100000| - 1 byte。<len>字段占用1个字节,值为0xE0,后面的数据<data>存储为8个字节的int64_t类型。
|11110000| - 1 byte。<len>字段占用1个字节,值为0xF0,后面的数据<data>存储为3个字节长的整数。
|11111110| - 1 byte。<len>字段占用1个字节,值为0xFE,后面的数据<data>存储为1个字节的整数。
|1111xxxx| - - (xxxx的值在0001和1101之间)。这是一种特殊情况,xxxx从1到13一共13个值,这时就用这13个值来表示真正的数据。注意,这里是表示真正的数据,而不是数据长度了。也就是说,在这种情况下,后面不再需要一个单独的<data>字段来表示真正的数据了,而是<len>和<data>合二为一了。另外,由于xxxx只能取0001和1101这13个值了(其它可能的值和其它情况冲突了,比如0000和1110分别同前面第7种第8种情况冲突,1111跟结束标记冲突),而小数值应该从0开始,因此这13个值分别表示0到12,即xxxx的值减去1才是它所要表示的那个整数数据的值。
6.3、quicklist快速列表
quicklist本身是一个双向无环链表,它的每一个节点都是一个ziplist。
为什么这么设计呢?
- 双向链表在插入节点上复杂度很低,但它的内存开销很大,每个节点的地址不连续,容易产生内存碎片。
ziplist是存储在一段连续的内存上,存储效率高,但是它不利于修改操作,插入和删除数都很麻烦,复杂度高,而且其需要频繁的申请释放内存,特别是ziplist中数据较多的情况下,搬移内存数据太费时!
Redis综合了双向链表和ziplist的优点,设计了quicklist这个数据结构,使它作为list键的底层实现。接下来,就要考虑每一个ziplist中存放的元素个数。
1、quicklist的数据结构
typedef struct quicklist {
quicklistNode *head;//指向头结点
quicklistNode *tail;//指向尾节点
unsigned long count; /* 列表中所有数据项的个数总和 total count of all entries in all ziplists */
unsigned int len; /* quicklist节点的个数,即ziplist的个数 number of quicklistNodes */
int fill : 16; /* / / ziplist大小限定,由list-max-ziplist-size给定 fill factor for individual nodes */
unsigned int compress : 16; /* 节点压缩深度设置,由list-compress-depth给定 depth of end nodes not to compress;0=off */
} quicklist;
//双向链表数据结构
typedef struct quicklistNode {
struct quicklistNode *prev;//前继节点
struct quicklistNode *next;//后继节点
unsigned char *zl; // 数据指针,如果没有被压缩,就指向ziplist结构,反之指向quicklistLZF结构
unsigned int sz; /* 表示指向ziplist结构的总长度(内存占用长度)ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* 编码方式,1--ziplist,2--quicklistLZF RAW==1 or LZF==2 */
unsigned int container : 2; /* 预留字段,存放数据的方式,1--NONE,2--ziplist NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /*解压标记,当查看一个被压缩的数据时,需要暂时解压,标记此参数为1,之后再重新进行压缩 was this node previous compressed? */
unsigned int attempted_compress : 1; /*测试相关 node can't compress; too small */
unsigned int extra : 10; /* 扩展字段,暂时没用 more bits to steal for future usage */
} quicklistNode;
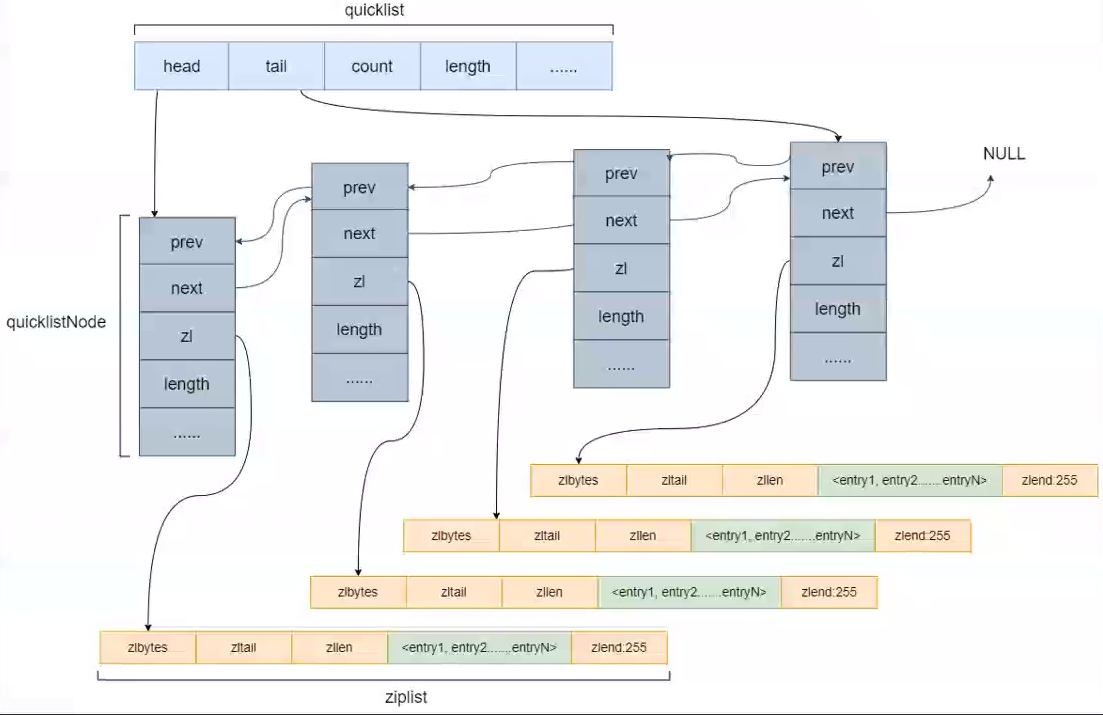
2、ziplist中的元素个数设定
redis.conf
list-max-ziplist-size -2
后面的数字可正可负,正、负代表不同函数,其中,如果参数为正,表示按照数据项个数来限定每个节点中的元素个数,比如3代表每个节点中存放的元素个数不能超过3;反之,如果参数为负,表示按照字节数来限定每个节点中的元素个数,它只能取-1~-5这五个数,其含义如下:
-1 每个节点的ziplist字节大小不能超过4kb
-2 每个节点的ziplist字节大小不能超过8kb
-3 每个节点的ziplist字节大小不能超过16kb
-4 每个节点的ziplist字节大小不能超过32kb
-5 每个节点的ziplist字节大小不能超过64kb
3、压缩操作
在quicklist的源码中提到了一个LZF的压缩算法,该算法用于对quicklist的节点进行压缩操作。list的设计目的是能够存放很长的数据列表,当列表很长时,必然会占用很高的内存空间,且list中最容易访问的是两端的数据,中间的数据访问率较低,于是就可以从这个出发点来进一步节省内存用于其他操作。Redis提供了一下的配置参数,用于表示中间节点是否压缩。
list-compress-depth 0
0 特殊值,表示不压缩
1 表示quicklist两端各有一个节点不压缩,中间的节点压缩
2 表示quicklist两端各有两个节点不压缩,中间的节点压缩
3 表示quicklist两端各有三个节点不压缩,中间的节点压缩
以此类推。
7、hash数据结构
hash数据结构底层实现为一个字典(dict),也是RedisDB用来存储K-V的数据结构,当数据量比较小或者单个元素比较小时,底层用ziplist存储,数据大小和元素数量阈值可以通过如下参数设置:

哈希对象保存的所有键值对的键和值的字符串长度都小于64字节
哈希对象保存的键值对数量小于512个
底层用`ziplist`存储

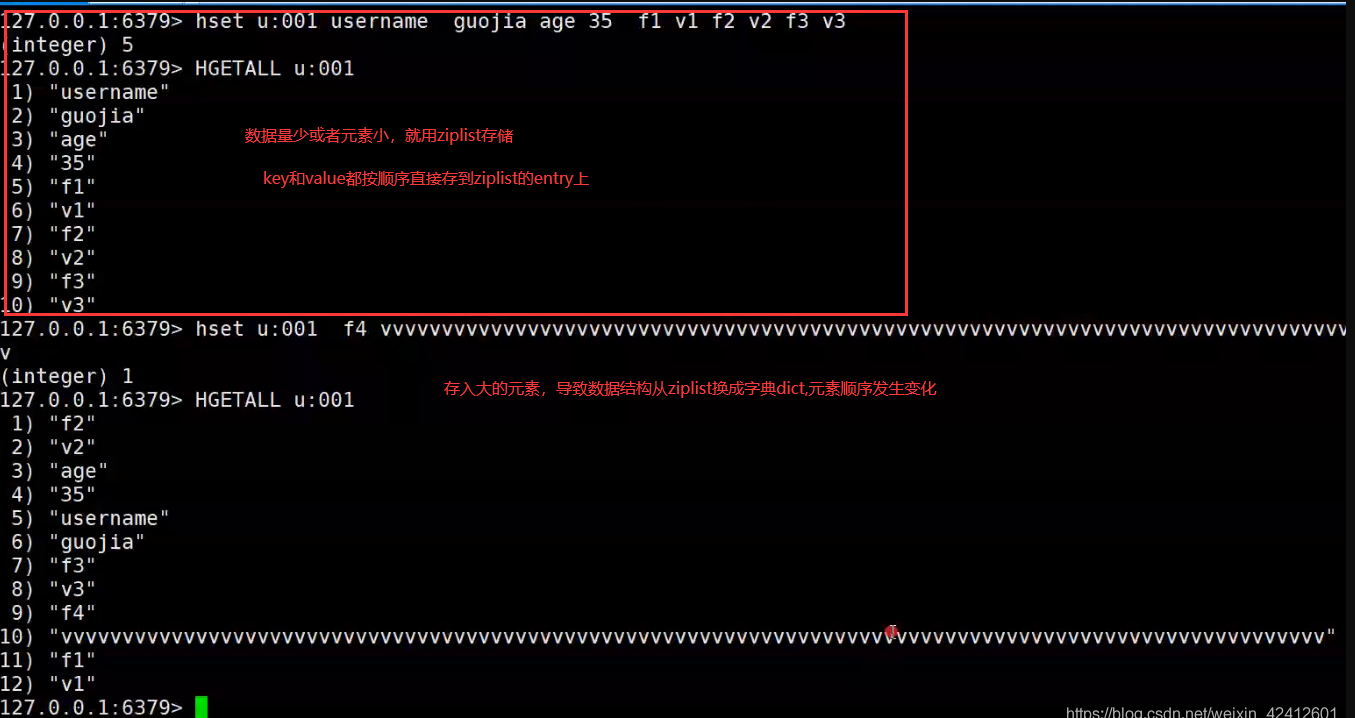
字典(dict)的数据结构3.1中有。
set与hset有什么区别?
1、set可以设置过期时间,hset不行
2、hset如果不断的添加数据,当hash表dictht的size等于used时【默认size=4】,就会扩容,每次都扩容一倍,当有非常多的key的时候,需要进行分片,分到不同的hash里面,避免频繁的扩容
8、set数据结构
set为无序的,自动去重的集合数据类型,set数据结构底层实现为一个value为null的字典dict,当数据可以用整形表示时,set集合将被编码为intset数据结构。两个条件任意不满足时,set将用dict存储数据:
1、元素个数少于set-max-intset-entries 512
2、元素无法用整形表示
集合类型的内部编码有两种:
1、字典(哈希表)
2、intset(整形集合)
体验set:
127.0.0.1:6379> sadd aset a b c d e f
(integer) 6
127.0.0.1:6379> smembers aset //无序
1) "b"
2) "c"
3) "d"
4) "a"
5) "f"
6) "e"
127.0.0.1:6379> sadd cset 1 2 3 4 5 6 7 8
(integer) 8
127.0.0.1:6379> smembers cset //有序
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "8"
127.0.0.1:6379> object encoding bset
"hashtable"
127.0.0.1:6379> object encoding cset
"intset"
8.1、intset数据结构
整形集合intset是一个有序的,存储整形数据的结构,并且可以保证不会出现重复数据
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
encoding : 顾名思义,intset编码。
- redis根据整型位数将intset分为
INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT64三种编码。 - 编码为
INTSET_ENC_INT16,contents里的元素,每个占两个字节 - 如果
INTSET_ENC_INT16有一个元素超过了两个字节,那么会进行扩容,扩容成INTSET_ENC_INT32编码,4个字节能表示的数据
length : 集合元素大小,时间复杂度由O(n)->O(1)。
contents : 元素存储数组。
9、ZSet数据结构
应用:排行榜。
https://blog.csdn.net/lunwuciyu/article/details/78113927
https://blog.csdn.net/haoxiaoyong1014/article/details/81533389
https://bbs.gameres.com/thread_461758.html
ZSet为有序(优先score排序,score相同则用元素字典序来排序)的,自动去重的集合数据类型,ZSet数据结构底层实现为字典(dict)+跳表(skiplist),当数据比较少时,用ziplist编码结构存储,同时满足以下两个条件的时候使用ziplist,其他时候使用skiplist,两个条件如下:
- 有序集合保存的元素数量小于128个
- 有序集合保存的所有元素的长度小于64字节
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
9.1、skiplist跳表数据结构
1、假设有一个链表查询73号元素,只能从头遍历过来,时间复杂度O(n)

2、优化,往上加一个索引层,每隔两个元素,提取一个索引到上一层,被抽出来的这级叫做索引层。
所以要找到73,就不需要将78前的结点全遍历一遍,只需要遍历索引,找到70,然后发现下一个结点是78,那么73一定是在 [70,78] 之间的
3、再加一层呢,跟前面建立一级索引的方式相似,我们在第一级索引的基础上,每两个结点就抽出一个结点到第二级索引。此时再查找73,只需要遍历 4 个结点了,需要遍历的结点数量又减少了。
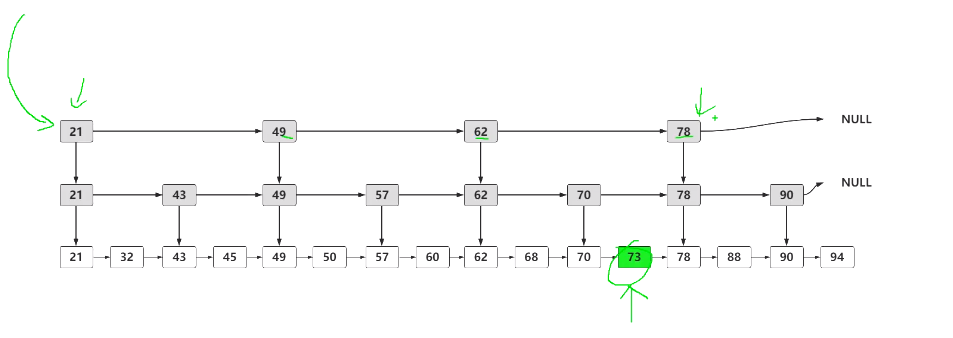
当结点数量多的时候,这种添加索引的方式,会使查询效率提高的非常明显。
跟二分查找很类似。
时间复杂度为logn
这种链表加多级索引的结构,就是跳表。
9.2、ZSet的skiplist跳表实现
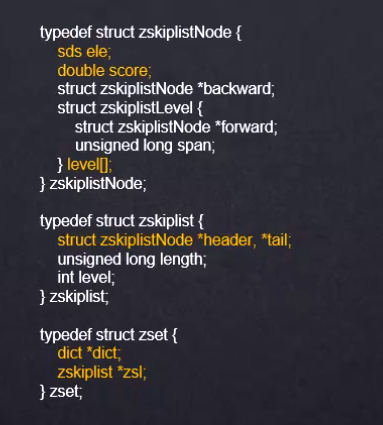
ele:存项的值
score:存项的分数
*backward:反序指针,zset的跳表也是一个双向链表
level:层高
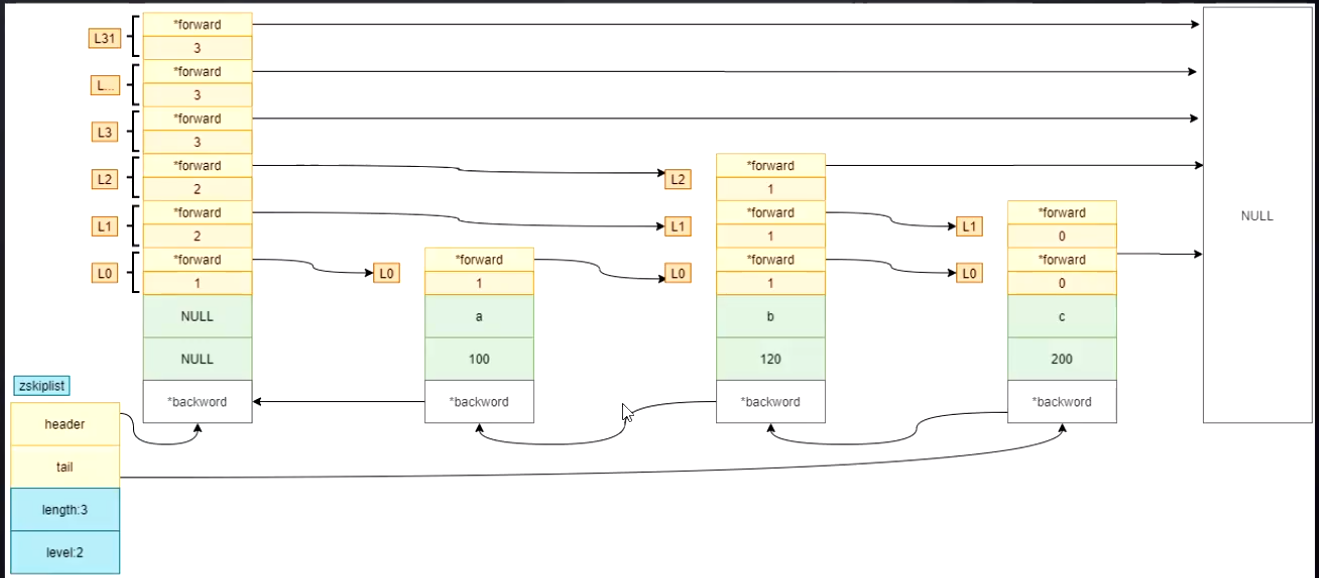
头结点是空的,header指向头结点,tail指向尾节点
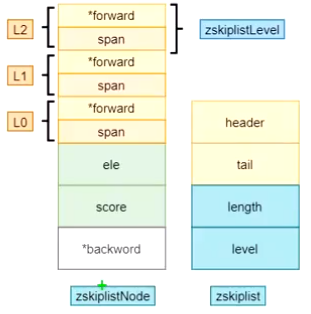
跳表索引层的属性span,表示跨域几个元素提取一个索引到上一层
https://blog.csdn.net/WhereIsHeroFrom/article/details/84997418?utm_medium=distribute.pc_relevant.none-task-blog-OPENSEARCH-1.edu_weight&depth_1-utm_source=distribute.pc_relevant.none-task-blog-OPENSEARCH-1.edu_weight
zset应用
https://blog.csdn.net/igo9go_zq/article/details/79567121?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.edu_weight&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.edu_weight
1、单个字段排行榜
1、设置数据
127.0.0.1:6379> zadd lb 89 user1
(integer) 1
127.0.0.1:6379> zadd lb 95 user2
(integer) 1
127.0.0.1:6379> zadd lb 95 user3
(integer) 1
127.0.0.1:6379> zadd lb 90 user4
(integer) 1
2、查看某个玩家分数以及排行榜
127.0.0.1:6379> zscore lb user2
"95"
//zrevrange分数由高到低排序的,zrange是按照分数由低到高排序
//起始位置和结束位置都是以0开始的索引,且都包含在内。如果结束位置为-1则查看范围为整个排行榜。
//带上withscores则会返回玩家分数。
127.0.0.1:6379> zrevrange lb 0 -1 withscores
1) "user3"
2) "95"
3) "user2"
4) "95"
5) "user4"
6) "90"
7) "user1"
8) "89"
127.0.0.1:6379> zrevrange lb 0 1 withscores
1) "user3"
2) "95"
3) "user2"
4) "95"
2、多个字段排序
例如:按积分倒序,积分一样的,按注册时间升序,注册时间一样的,按登录次数倒序,这种稍微复杂的情况, redis 暂时没有方法直接排序了,为解决这个问题,需要一个巧妙点的处理。
例如:

分数为:85(2000000000 - 1570094188)0006, 存储的时候为 zdd xxx 854299058120006 B, 执行 zrevrangebyscore xxx 1 100 WITHSCORES LIMIT 1,10 直接倒序筛选 10 个结果。
注册时间获取:
// 第一个字符串是当前时间(以 UNIX 时间戳格式表示),而第二个字符串是当前这一秒钟已经逝去的微秒数。
127.0.0.1:6379> time
1) "1603508223"
2) "573225"
构造数据:
表示用户1和用户2分数都是85的时候,注册时间也相同的时候,就按照登录次数排序了
127.0.0.1:6379> zadd multi_field_sort 854299058120006 user1
(integer) 1
127.0.0.1:6379> zadd multi_field_sort 854299058120056 user2
(integer) 1
127.0.0.1:6379> zrevrange multi_field_sort 0 -1 withscores
1) "user2"
2) "854299058120056"
3) "user1"
4) "854299058120006"